

If you take a close look at the different reference architectures and best practices documents surrounding the Zero Trust methodology, you’ll find that the big question they all try to answer is where to start a ZT initiative. Once you and your organization understand and buy into the benefits of implementing a Zero Trust posture across your IT infrastructure, you’ll naturally be working with finite time, budget, and resources. Engaging in a sweeping project focusing on instituting Zero Trust across your entire infrastructure isn’t workable or even recommended. You’ll want to focus your initial initiative—perhaps even a pilot or proof of concept—to a particular subset of the overall environment, assess the outcome, acquire lessons learned, and then adjust from there.
This blog post is 4th in a series focused on the increasingly popular Zero Trust cybersecurity framework and data-centric security.
Often, in a given situation that demands action from us, whether in business or in our personal lives, we weigh which course to take based on the one providing maximum benefit with minimum expenditure of effort. The concept of going after the ‘low-hanging fruit’ reflects this human proclivity, but sometimes we hint at the low-hanging-fruit course of action pejoratively, as though it betrays a lack of drive or enthusiasm, that it reflects inherent laziness to do the right thing. Not true! Maybe if we just rephrase it a bit, it sounds a little better? Looking at the situation from a cost-benefit perspective often points you to the biggest bang for your buck, and in business as well as in life that’s usually the smartest thing to do.
The two areas that are usually ripe for starting a Zero Trust initiative are networks and users. In the US DoD’s reference architecture, these are two of the main ZT pillars. The reason for businesses to start here—apparent at least to me—is that networks are the main conduit into your IT environment, and active users are driving a large portion of all that network traffic (sure, automated workflows and applications account for a portion of it). The thinking is probably this: best to continue with the traditional approach of building strong borders and protected perimeters around your IT infrastructure, only making them more granular and microsegmented, and then challenge users more frequently as they traverse different segments. In this way, we keep unwanted users from accessing our sensitive data and resources.
Microsegmentation is a way to encourage the type of isolation and challenge—to eliminate inherent trust—that is at the core of a Zero Trust approach. Rather than establishing broad network zones so that users who gain access have fairly unfettered use of the data and resources within that zone, micro-segmentation shrinks these zones down so that inherent rights to anything and everything are further restricted to smaller and smaller subsets of data and resources. Remember our castle analogy from #3 in this series? Microsegmentation is the cyber-equivalent of lots of different walled off areas, lots of different “challenge” points, and lots more monitoring of ingress and egress points as well as perimeters around it all.
If Zero Trust is about acknowledging that threat actors have or soon will breach your perimeters, isn’t constructing more perimeters just, well, more of the same? And recall what those hackers are really after. They want your sensitive data, not the IT resources they use as stepping stones to get to that data. So again, why not protect the data first, and then move to the other areas of the IT infrastructure, if you’re searching for a starting point?
In the past, the answer to that question has been that data-centric security, or applying protections directly to the data itself such as encryption and tokenization, is too expensive and too difficult to implement and operate. I want to deal with the first bit of pushback here, then will address difficulty of implementation and operation in my 5th and last entry in this series.
I’ll focus the cost-benefit analysis on network microsegmentation versus data-centric protection in the form of next-generation tokenization. If you think about microsegmenting (shrinking down your network zones), the driving principle is that more granularity is better than less granularity, with an increased number of control points to challenge and authenticate. But how much granularity is enough? Well, more is better, so the tendency might be to continue to microsegment in an increasing cycle of network equipment upgrades and additional operational complexity. This might be fine in a small- or perhaps medium-sized IT environment. However, for large enterprises, the ones with incredibly complicated networks accommodating tens or hundreds of thousands of users both centralized and remote, the costs of this ever-increasing granularity would start to look like an exponential growth curve. At some point, every enterprise would cap the effort (I call this the enterprise break-point, or that point at which enough granularity is achieved within acceptable costs). That curve looks something like this:
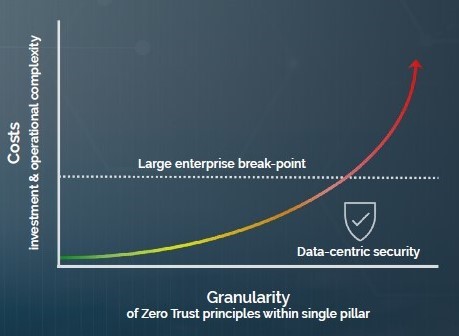 No matter where that break-point is for your organization, you have to realize one thing: you still have not protected what threat actors are really after, which is your data. You’ve invested into a lot of segmentation, and you’ve created a lot of complexity while establishing more control points, but you haven’t done anything to ensure that the data itself is safe. And remember, what’s at the core of Zero Trust thinking? Threat actors will get around or through your perimeters. What then?
No matter where that break-point is for your organization, you have to realize one thing: you still have not protected what threat actors are really after, which is your data. You’ve invested into a lot of segmentation, and you’ve created a lot of complexity while establishing more control points, but you haven’t done anything to ensure that the data itself is safe. And remember, what’s at the core of Zero Trust thinking? Threat actors will get around or through your perimeters. What then?
That’s where data-centric security such as tokenization comes into play. Tokenization allows you to achieve the utmost granularity, because with the power of advanced intelligence and automation you can tokenize individual sensitive data elements so that nobody can compromise the data. Nothing sensitive needs to be in the clear or even de-protected, because tokenization retains data format so that users and applications can still work with data while sensitive elements remain tokenized.
So why is data-centric security represented as more cost-effective than granular microsegmentation in the illustration above? We can cite our own customer experiences, who have been in the process of various forms of network modifications to achieve a better level of granularity but decided to start first with upgrading data security, at a much better price point than they even expected. One of our customers was attempting to create this level of granular micro-zones between central office and individual stores with back-to-back firewalls, but instead invested 1/3 the cost into our data-centric security platform and achieved a much more granular level of security in the process. And this doesn’t include millions more in savings because of the easing of compliance audits and avoiding the operational complexity that would have ensued with their original plan. This doesn’t mean that more granular network segmentation or better identity and access management solutions aren’t warranted. We’re talking about a cost-benefit analysis for the starting point of your Zero Trust journey: the low-hanging fruit.
Now, I need to tie all of this up into a discussion of how implementing data-centric security has changed for the better, leads to more streamlined operations, and helps improve the cost-benefit outlook. Please come back for #5 as I talk about implementing data-centric security, how it helps you achieve more granular control at the data level, and ultimately how it makes sense as the starting point of your Zero Trust initiative.






